
Long-form
- End-to-end encrypted is a must, no way around it; the options for less-than-encrypted is a lot larger and well-served by e.g. my employer.
- Self-hostable because the history of this app segment revolves around shutdowns. I can spin up a new Ansible role for most containerized things in a blink.
- Command-line interface since I’m inclined to make helper scripts for most workflows.
- Easy to use for the receiver because not everybody in my life can install something on the command line, making the web the optimal delivery mechanism.
- Expiring uploads because an out-of-band send shouldn’t exist long-term and because there’s better options for perpetual file hosting.
- The global address may change. In fact, it’s guaranteed on my home network because the AT&T modem randomly hands out one of its non-reserved /64s depending on the mood it’s in.
- It’s a lot to memorize and type. Focusing on just the interface identifier portion is all that really matters in a local network. That part’s unlikely to change, and can be hard-coded on individual devices if desired.
- One or two (or more) global addresses.
- One or more local addresses (ULAs). Yes, local addresses are a thing!
- A global address prefix allocated by the ISP. For example,
2001:db8:496b:942::/64. - A local address prefix. For example,
fd00::/64. There’s a suggested algorithm for generating these but that’s overkill for a home network unlikely to ever need to network with another privately. Keep it simple. - Set the WAN interface to use DHCPv6 to get a /64 prefix delegation.
- Set the LAN interface to “Track Interface” from the WAN interface.
- Add a virtual IP address (like
fd00::1/64) to the router. - Add a router announcement subnet (under DHCPv6/RA) of
fd00::/64. The one the LAN tracks will automatically be announced, even if not entered. - Set the DNS server (under DHCPv6/RA) to
fd00::1/64. - Make sure you’ve got IPv6-allowed-to-
*rules in your LAN. -
I’ve spent hours searching for documentation about the performance impact of drawing outside bounds, and there’s not a lot of detail available. ↩︎
-
Often in Apple SDKs, the headers contain information the documentation is missing. This is from the UIView headers:
Constraints do not actually relate the frames of the views, rather they relate the “alignment rects” of views. This is the same as the frame unless overridden by a subclass of UIView.
I did not notice this and I am sure many others are missing this key piece of documentation. ↩︎
- Improving the performance of having a shadow
- Creating shadows that don’t match the contents of the view. Check out Apple’s Using Shadow Path for Special Effects.
- Launch Keychain Access (inside your Utilities folder).
- In the “File” menu, choose “New Keychain” and note the secure password you use.
- From your “login” keychain, locate and select both:
- Your distribution certificate—the one from Apple.
- Your private key, which you generated, likely a sub-item.
- Copy the two items to your new keychain by holding Option (⌥) and dragging them into the keychain.
- Tell the system to use our keychain, and
- Use the password environmental variable to unlock our keychain.
- Never concatenate strings to form sentences. Many languages have different sentence structure or gender rules than English and you cannot just substitute a single word or phrase in for any other.
- Never use substrings for searching in an original string. If you depend on the standalone translation of “Privacy Policy” matching the sentence version, you will likely find translators do not understand this intent. You may also find the same search term multiple times (imagine if the user searched for “Search”).
- To handle the current locale changing, or the dynamic type setting changing, reload your UI when observing:
NSCurrentLocaleDidChangeNotificationUIContentSizeCategoryDidChangeNotification
- To represent dates, durations, distances, lengths, etc., use an appropriate formatter.
- To create your own date formats, use
+dateFormatFromTemplate:options:locale:on NSDateFormatter. Remember that these need recreating if the locale changes. - To combine a first and last name, use
ABPersonGetCompositeNameFormatForRecordwith a temporaryABPersonRef, or use the newNSPersonNameComponentsFormatter. - For sending non-user-facing data to a server, use
en_US_POSIXas your locale. - I had 2 referrals, one processed (the gift card) and one pending (a few days old).
- Referral #1 was activated a few days before the data offer started, and didn’t qualify.
- Referral #2 would give me a $10 discount on my existing unlimited data.
- If I ended my existing unlimited data, referral #2 would be nullified.
- No refer-a-friend rep would have added unlimited data to my account.
-
I dislike that Twitter direct messages require following the sender. I gave up after a few days because I was tired of seeing their tweets, so perhaps they tried to respond some time later. I doubt it. ↩︎
- From the gateway, navigate to:
Settings>Firewall>Applications, Pinholes and DMZ. - Choose the router from the list. It will appear as a link named “Choose <name>.”
- Change its setting below to “Allow all applications (DMZplus mode).”
- Navigate to
Settings>LAN>IP Address Allocation. - Locate the settings box for the router.
- Change its “Address Assignment” from “Private” to “Public.”
- Image IO files are on average 20% (but up to 30%) smaller1.
- Image IO takes about 2x longer.
-
The UIImage version has a color profile, while the Image IO version does not. However, running both files through Image Optim produces a 7% reduction on both, so I am choosing to ignore this difference. Afterall, you can’t remove the color profile anyway! ↩︎
-
The following are possible types you can use, from the documentation:
↩︎Constant UTI type kUTTypeImagepublic.image kUTTypePNGpublic.png kUTTypeJPEGpublic.jpeg kUTTypeJPEG2000public.jpeg-2000 (OS X only) kUTTypeTIFFpublic.tiff kUTTypePICTcom.apple.pict (OS X only) kUTTypeGIFcom.compuserve.gif
Using Uptime Kuma push monitors
Uptime Kuma has a “push” monitor type which supports sending in status updates for something like a cron job to make sure it continues to execute. I use this for tasks like running backups or cleanup chores.
Aside: To avoid tying monitoring to my normal infrastructure, I’ve been successfully running Uptime Kuma on fly.io. I also recommend Cronitor for a similar commercial offering but its pricing doesn’t align well with my personal projects.
Normally to update Uptime Kuma you might append && curl … to invoke the monitor URL at the end of a script. I think this is a little too limiting, so I’ve written a small script that wraps an underlying command with a monitor update:
#!/bin/bash
if [ $# -lt 1 ]; then
echo "Usage: $0 <push_token> [command...]" >&2
exit 1
fi
push_token=$1; shift
start_time=$(date -u +%s%3N)
if [ $# -gt 0 ]; then
"$@" || exit
fi
end_time=$(date -u +%s%3N)
duration=$(($end_time - $start_time))
result=$(curl --fail --no-progress-meter --retry 3 "https://uptimekuma.example.com/api/push/$push_token?ping=$duration" 2>&1)
if [ $? -ne 0 ]; then
echo "Failed: $result" >&2
fi
This script is invoked with the token and an optional underlying command to execute and report to Uptime Kuma when the command is successful along with its execution time as the ping property. For example:
kuma 3EpwDA93fC docker system prune -a -f
I’ve automated this using the ansible-uptime-kuma Ansible collection to automatically create “push” monitors for recurring jobs and “http” monitors for web-facing services. This ends up looking something like the following for a push monitor:
- name: Store the monitor name
set_fact:
monitor_name: "{{ inventory_hostname }}-borgmatic"
- name: Create Uptime Kuma push monitor
delegate_to: 127.0.0.1
lucasheld.uptime_kuma.monitor:
api_url: "https://uptimekuma.example.com"
api_token: "{{ uptime_kuma_api_token }}"
type: push
name: "{{ monitor_name }}"
interval: 3600
- name: Get Uptime Kuma push monitor info
delegate_to: 127.0.0.1
lucasheld.uptime_kuma.monitor_info:
api_url: "https://uptimekuma.example.com"
api_token: "{{ uptime_kuma_api_token }}"
name: "{{ monitor_name }}"
register: monitor_info
- name: Set Uptime Kuma push token
set_fact:
push_token: "{{ monitor_info.monitors[0].pushToken }}"
- name: Create borg cronjob
cron:
name: "Borg backups"
job: "/usr/local/bin/kuma {{ push_token }} /usr/local/bin/borgmatic create"
minute: 33
This creates a monitor for my borgmatic cron and executes it hourly. When it fails to check in, Uptime Kuma sends me notifications, and when it succeeds it keeps track of how long it takes to execute. Perfect!
X-Forwarded-For sanitization in Caddy
When reverse proxies like Cloudflare proxy a request, they communicate the original request’s source using the X-Forwarded-For header. This can be dangerous: they will augment a value from the original request producing a value like Spoofed, Cloudflare-Given.
When adding another reverse-proxy like Caddy into the mix you send upstream a value like Spoofed, Cloudflare-Given, Caddy-Given. This is messy; I don’t want to teach upstream what the history of the request is and which proxies are valid.
The Caddy docs on reverse_proxy indicate a way to fix this is by creating transformation rules within Cloudflare to strip the Spoofed value in certain situations. This requires too much work and remembering to it when configuring a new site.
A tactical way to accomplish this is to use the semantics of the header value itself. Our downstream, trusted proxies are either setting the value to IP or appending , IP so we can disregard the earlier parts of the header value entirely. In a Caddyfile, this is done using the request_header directive:
# Remove older X-Forwarded-For values since we only want to
# trust the last one iif we're going to trust at all.
# Regex information: https://regex101.com/r/KZknzS
request_header X-Forwarded-For "^([^,]*,)*\s*([^,]+)$" "$2"
# Later on in the server configuration somewhere
reverse_proxy upstream:1234 {
# Which proxies allow X-Forwarded-For to go upstream
trusted_proxies 198.51.100.0/24
}
When a direct request to Caddy comes in with a fake X-Forwarded-For header, it’s not passed upstream because it’s not a trusted proxy. This is the normal behavior.
When a request comes in via a trusted proxy with an X-Forwarded-For value like Spoofed, Cloudflare-Given we pass to upstream Cloudflare-Given, Caddy-Given without the Spoofed part.
Sending text and files securely
My desires for sharing something like credentials are all over the place:
Firefox Send was fantastic. Mozilla killed it off due to moderation issues, and likely because they’re unable to ship and maintain products that aren’t Firefox itself these days. It sets the tone for the rest of these services because it leveled up the space. I miss it.
Wormhole.app is the spiritual successor of Firefox Send but lacks a command-line interface and is not open source. Normally I’m not one to bemoan something like this being closed source and free but I’d much rather pay for a service than watch yet another thing shut down.
magic-wormhole is a great peer-to-peer-only command-line option, and I often use it to send files between my own machines and servers, but it requires both sides be online at the same time and requires installing it on the device. Wormhole.app – almost certainly stealing the name from this one – also does peer to peer through WebRTC.
FileSend by Standard Notes works well, is self-hostable, but has a rather limited scope of impact and community around it, eliminating any possible extension into the command-line world. Difficult to host publicly without allowing anonymous uploads.
Bitwarden Send is self-hostable, most easily via Vaultwarden which is what I use, supports large file sizes, has a decent command-line integration, and has a great option for text-only sends as well. The biggest issue is interface: authenticating into a Bitwarden instance via master password has to happen before you can send the files, which adds overhead to working with it both on the command line and web/clients.
Send (with many hosted instances) is a fork of the defunct Firefox Send codebase. It is also difficult to host without allowing anonymous uploads. ffsend by the same author is a capable command line interface, and supports using Basic Auth in front of the instance. In my testing, requiring auth on /api/ws is enough to prevent anonymous upload but still allow downloading.
For my personal use, I went with self-hosting Send on a cheap VPS that I’ve already got a few services running on.
Were I picking something for sharing within a team/family/company I’d probably go with Bitwarden, since it’s so extensible and likely a good choice for general password storage/sharing as well.
I’ll probably recommend Wormhole.app for one-off sends from others as long as it exists. Hopefully that’s for a little bit longer than Firefox’s attempt lasted.
IPv6 in a home environment
IPv6 addresses are broken up into two halves: the network prefix and the interface identifier. It looks something like this, in hex notation:
aaaa:bbbb:cccc:dddd:1111:2222:3333:4444
The alphabetical and bold parts of this are the network prefix and the numerical are the interface identifier.
The network prefix is then divided into a routing prefix (controlled by the ISP) and a subnet prefix (controlled by home network). ISPs will allocate a routing prefix of (in CIDR notation) /56, /60 or /64—meaning the first 56, 60 or 64 bits are reserved—and the rest are available to play with for the subnet. Routers generally request a /64 from upstream by default, which is one IPv6 network.
The interface identifier is picked by the device connecting to the network using SLAAC after being told which network prefixes are available from a router announcement. DHCPv6 is typically overkill and unnecessary on a home network.
In IPv4 a private address space like 192.168.0.0/16 is used locally and translated to a public address on the internet via NAT since there’s way too few IPv4 addresses for the number of devices that need to get on the internet. This NAT requirement also turned into a benefit in a home network as it is easier to use and memorize these shorter addresses.
Every IPv6 guide bemoans this private address desire and instead suggests adopting and using global addresses instead. The advice on the internet about IPv6 addressing is almost entirely focused on businesses who request and receive a static IPv6 prefix from a regional registry and completely overlook the benefits to home users without major infrastructure to handle configurations. However, as a home user:
Unlike IPv4, devices can and will have multiple simultaneous IPv6 addresses:
For global addresses, non-end-user devices will likely choose a random interface identifier and rotate it regularly to avoid external tracking. For servers and for local addresses, devices will use a modified version of their MAC address (EUI) to have a stable interface identifier.
It’s important, then, to allow devices to have a local address. This is shockingly not the default on consumer routers. The router should announce:
To implement this on pfSense, assuming “turn on IPv6” is checked:
The router will now periodically and when queried announce to the network which address prefixes to use, what DNS server to talk to, and various other configuration.
The LAN interface of the router can now be addressed at fd00::1 and network devices will pick stable addresses in the fd00::/64 network (e.g. fd00::a9cd:efff:feab:cdef); they can be used in configurations without worrying about changing, and IPv6 will continue to work locally even without internet.
Some devices may also advertise their own local prefixes; Thread uses IPv6 so aggressively that its devices will often send out an RA of a random local prefix if they do not pick one up on their own. Apple HomePod minis are particularly guilty of this, and it was tough to narrow down that they were the cause.
Creating iOS simulators in bulk
To work around Xcode’s disinclination for creating new simulators, I wrote a script which deletes all the current simulators and then creates every possible simulator. It’s relatively straightforward because simctl has a decent JSON interface which makes processing the state a lot nicer:
#!/usr/bin/env fish
# Just to make it obvious when using the wrong version
printf "Using Xcode at %s\n\n" (xcode-select -p)
echo "Deleting all simulators..."
xcrun simctl shutdown all >/dev/null
xcrun simctl delete all >/dev/null
printf "...done\n\n"
echo "Creating new simulators..."
# You could also add 'appletv' to this list
for runtime in ios watch
set -l runtimes (xcrun simctl list runtimes $runtime available -j | jq -c '.runtimes[]')
for runtime in $runtimes
set -l runtime_version (echo $runtime | jq -r '.version')
set -l runtime_identifier (echo $runtime | jq -r '.identifier')
set -l supported_devices (echo $runtime | jq -c '.supportedDeviceTypes[]')
for device in $supported_devices
set -l device_name (echo $device | jq -r '.name')
set -l device_identifier (echo $device | jq -r '.identifier')
set -l display_name "$device_name ($runtime_version)"
printf \t%s\n $display_name
xcrun simctl create $display_name $device_identifier $runtime_identifier >/dev/null
end
end
end
printf "...done\n\n"
The only thing missing here is device pairing – connecting a watch and phone together. Since there’s limitations around the number of devices which can be paired together, I find this a bit easier to still do manually.
Making shift-space send page up and other key mappings in iTerm2
A common problem when I am paging through less output is that, while the space key will go down a page, the shift-space shortcut does not go up. The underlying reason is terminals are strings of text and date back decades and many key combinations are archaic sequences.
Shift-space is is one of these cases. While the space key inserts visible text, the shift-space variant doesn’t have a unique character. This requires hoping particular app can handle the sequence CSI 32;2 u (which may look like ^[[32;2u; this is part of a proposal known as CSI u), or changing the key map in the terminal. I went for the latter.
I use iTerm2, which is stellar for many reason. Its key mapping control can do what we want here, and looks like so:
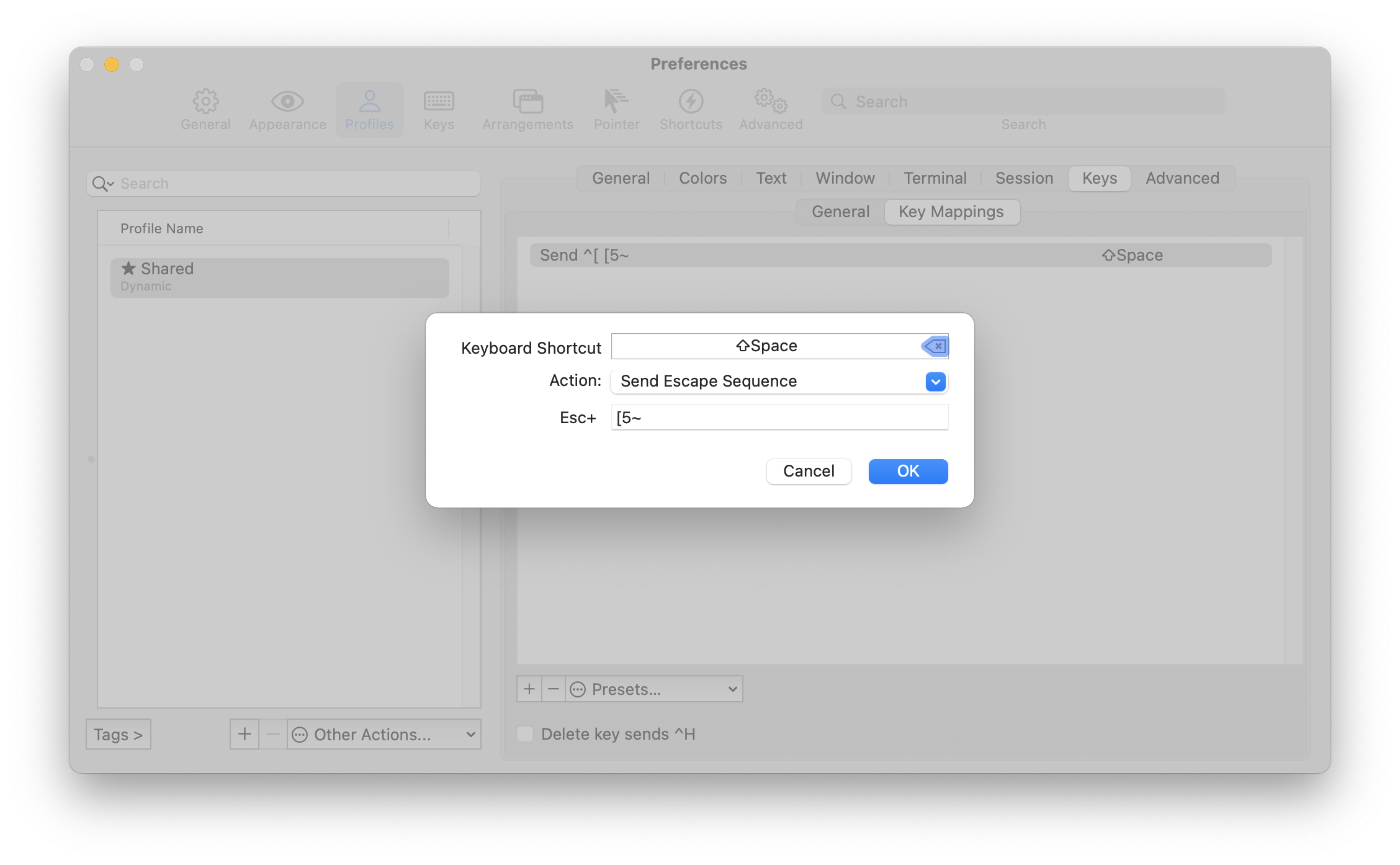
You can figure out what escape sequence to send for a particular existing key combination using your shell by entering a key-reading mode and then the shortcut.
For fish, this looks like:
$ fish_key_reader
Press a key: <page up>
hex: 1B char: \c[ (or \e)
( 0.037 ms) hex: 5B char: [
( 0.018 ms) hex: 35 char: 5
( 0.020 ms) hex: 7E char: ~
bind -k ppage 'do something'
bind \e\[5~ 'do something'
For bash or zsh, this looks like:
$ <ctrl-v><page up>
# transitions to
$ ^[[5~
Both of these tell us that the escape sequence is CSI 5 ~, so that’s the sequence we want to tell iTerm to send. This looks like ESC+[5~ in its UI.
iTerm2 also has Dynamic Profiles, which allows text-based management of its profile settings; this lets me keep changes intentional and preserves the history in git. Adding this same keymap there looks something like this (with other content elided):
{
"Profiles": [
{
"Guid": "22b93c98-1383-440b-8224-d1c3f653a850",
"Name": "Profile Name",
"Keyboard Map": {
"0x20-0x20000-0x31": {
"Version": 1,
"Action": 10,
"Text": "[5~",
"Label": "PageUp for Shift-Space"
}
}
}
]
}
Managing preference plists under Chezmoi
Chezmoi handles my dotfiles, and it allows me to painlessly go to great levels of configuration management across machines. There’s one difficult type of configuration to deal with on Mac, though: binary .plist files.
Take Soulver, for example, which stores its font settings in UserDefaults. This results in a binary plist in ~/Library/Preferences which contains information changed on each run of the app. It is a great example of what not to check into source control.
My solution is using a modify script, which Chezmoi calls with the current version of the file looking for a modified version in response. The script for Soulver is stored in modify_private_app.soulver.mac.plist:
source "$(chezmoi source-path)/path/to/plist.sh"
pl SV_CUSTOM_FONT_NAME -string CUSTOM_FONT
pl SV_CUSTOM_FONT_POST_SCRIPT_NAME -string "Input-Regular"
pl SV_FONT_SIZE -integer 16
This is relatively stable, but more prone to breaking than a concretely-defined settings file format, of course. This uses a helper script named plist.sh which acts as a thin wrapper around plutil while minimizing the amount of boilerplate:
set -e
TMPFILE=$(mktemp)
trap "cat $TMPFILE; rm $TMPFILE" EXIT
function pl() {
# test before setting because plutil _will_ mutate the file
# macOS 12.+, you can use plutil like:
# CURRENT=$(plutil -extract $1 raw $TMPFILE 2>/dev/null || :)
CURRENT=$(/usr/libexec/PlistBuddy -c "Print :$1" $TMPFILE 2>/dev/null || :)
if [ "$CURRENT" != "$3" ]; then
plutil -replace $* "$TMPFILE"
fi
}
cat <&0 >$TMPFILE
if [ ! -s $TMPFILE ]; then
# plutil will error if it encounters an empty file
# macOS 12.+ you can use plutil like:
# plutil -create binary1 $TMPFILE
echo "{}" | plutil -convert binary1 -o $TMPFILE -
fi
Now my Soulver settings are synced and updated using Chezmoi, and I don’t have to keep track of which apps I need to visit if I decide I want to play with a different font.
I recently looked at every programming font I could find; here are my favorites in order:
Technical debt that lasts forever
I noticed that ls output is sorted case-sensitively on macOS; that is, “abc” is sorted after “Xyz.” It doesn’t appear there are any mechanisms to get ls to do a case-insensitive sort, either. To work around this in a script I was writing, I looked to sort to do this for me, and stumbled upon the always-confusing flag:
-f,--ignore-case: Convert all lowercase characters to their uppercase equivalent before comparison, that is, perform case-independent sorting.
Which brings about the question: what does -f have to do with case-insensitive sorting? The answer to this part of the mystery is more apparent in the coreutils version, which describes it as:
-f,--ignore-case: fold lower case to upper case characters
So the -f short-form flag is for “fold.” Case folding is a mechanism for comparing strings while mapping some characters to others, or in this case mapping lowercase to uppercase using Unicode’s Case Folding table.
The long-form version of this flag was added in 2001, citing as “add support for long options.” The short-form version was added in 1993, likely for compatibility with some pre-existing Unix version. The first version of the POSIX standard in “Commands and Utilities, Issue 4, Version 2” (1994, pg. 647) doesn’t even use the word “fold,” defining it as:
-f: Consider all lower-case characters that have upper-case equivalents, according to the current setting of LC_CTYPE, to be the upper-case equivalent for the purposes of comparison.
Sadly, the oldest version of sort that I can find is from 4.4BSD-lite2, which describes it the same as macOS does now, also without the word “fold” in sight. I’m guessing some older, more ancient documentation for proprietary Unix is floating around somewhere that describes the flags, too.
Amusingly, the option you’d think would be the case-insensitive comparison flag, -i, is instead “ignore all non-printable characters.” This is a great example of picking a precise-but-confusing name for something and getting stuck with it until the end of time.
Fixing slow Firefox loading when using Pi-Hole
I run Pi-Hole to prevent clients on my network from loading dangerous or gross things like advertisements or tracking scripts. This normally works great: it functions on all devices without requiring configuration and I don’t need to think about it too often.
I’ve also been using Firefox a lot more often lately, partly because Big Sur introduced a lot of Safari regressions and sites like Twitter are broken regularly, and partly because I like the features it’s coming out with like HTTPS-only mode.
Unfortunately, Firefox and Pi-Hole do not play nicely together when it comes to certain websites. For example, when loading sfchronicle.com several of its trackers have performance issues:

When Firefox comes across a host which resolves to 0.0.0.0, it appears to have some kind of internal retry mechanism that, combined with HTML’s sequential loading of scripts, causes a cascading set of delays making loading take an extremely long time.
Fortunately, Pi-Hole’s behavior of returning 0.0.0.0 for disallowed hosts is configurable. Changing its BLOCKINGMODE to NODATA changes the resolution behavior from:
$ dig +noall +question +answer secure.quantserve.com
;secure.quantserve.com. IN A
secure.quantserve.com. 2 IN A 0.0.0.0
to:
$ dig +noall +question +answer secure.quantserve.com
;secure.quantserve.com. IN A
Instead of providing an IP address, the response we get is instead that there are no A records for the domain, and Firefox gives up a lot faster, taking a few milliseconds instead of a few seconds. The Pi-Hole documentation on blocking modes provides a caveat:
…experiments suggest that clients may try to resolve blocked domains more often compared to
NULLblocking…
The default blocking behavior (NULL) is returning 0.0.0.0. I have not come across any issues with this change, but I also don’t think I’d notice if DNS requests drastically increased on my network.
This doesn’t resolve all of the performance issues on the SF Chronicle in Firefox. Even using a non-Pi-Hole DNS server shows significant loading delays compared to Safari. This, at least, makes it painful instead of frustrating. As an aside, I am resentful that I’m paying $12 per month for a website that wants to inject the scummiest of Taboola-level ads on me.
Alignment rects in Auto Layout views
In the UIView documentation, Apple describes alignment rects:
The constraint-based layout system uses alignment rectangles to align views, rather than their frame. This allows custom views to be aligned based on the location of their content while still having a frame that encompasses any ornamentation they need to draw around their content, such as shadows or reflections.
At first glance, this feature feels unnecessary: views can draw outside their bounds seemingly without performance issues1. However, the differentiation between frame and alignment is a powerful, and easily overlooked, feature in Auto Layout.
Automatic with constraints
Views that use Auto Layout for positioning and sizing get alignment rect support for free via alignmentRectInsets. Unfortunately, going by the documentation, this is not evident2.
Let’s work through this using an example. The vertical line is going down the exact center of the container:
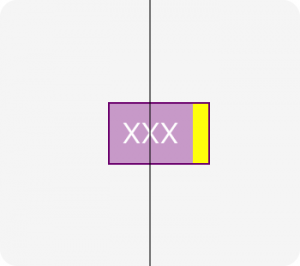
This view has a label and decorative yellow box to the side. Notice that we’re centering relative to the label, and not to the decorative box. This is accomplished with a very small amount of code:
override var alignmentRectInsets: UIEdgeInsets {
return UIEdgeInsets(top: 0, left: 0, bottom: 0, right: 10)
}
The constraints within the view can completely ignore this fact. With the insets set, the layoutMarginGuide and direct leading, trailing, etc., anchors are automatically inset. This is also true for constraints created via NSLayoutConstraint.
The entirety of the positioning for the view above looks like this:
label.translatesAutoresizingMaskIntoConstraints = false
NSLayoutConstraint.activate([
label.leadingAnchor.constraint(equalTo: layoutMarginsGuide.leadingAnchor),
label.trailingAnchor.constraint(equalTo: layoutMarginsGuide.trailingAnchor),
label.topAnchor.constraint(equalTo: layoutMarginsGuide.topAnchor),
label.bottomAnchor.constraint(equalTo: layoutMarginsGuide.bottomAnchor)
])
// alignmentRectInsets doesn't support RTL,
// so use left/right rather than leading/trailing
yellowBox.translatesAutoresizingMaskIntoConstraints = false
NSLayoutConstraint.activate([
yellowBox.topAnchor.constraint(equalTo: topAnchor),
yellowBox.bottomAnchor.constraint(equalTo: bottomAnchor),
yellowBox.leftAnchor.constraint(equalTo: rightAnchor),
yellowBox.widthAnchor.constraint(equalToConstant: alignmentRectInsets.right)
])
We can now apply whole-view effects, like the border in the example above, without having to create elaborate view hierarchies. The decoration is part of the view, not floating outside of it.
The only downside here is that alignmentRectInsets does not use the new NSDirectionalEdgeInsets introduced in iOS 11, so right-to-left support may need to look at effectiveUserInterfaceLayoutDirection.
Tappability
Apple recommends 44pt tappable areas for controls which are often designed to be aligned with other elements on the screen, often times closer than this tappable region.
To combat this problem, a common solution is overriding hitTest(_:with:) on the button to allowing it to tapped outside of its frame. This makes it hard to visualize where a screen is tappable when debugging the view.
Let’s solve this problem using alignment rects. A custom UIControl subclass can use the regular insets like the view example above. Unfortunately, UIButton does not use Auto Layout internally, so a small subclass is needed to handle the insets:
class IncreasedTappableButton: UIButton {
// one potential optimization is to calculate insets that would
// make the button >= 44.0 pt tall/wide
override var alignmentRectInsets: UIEdgeInsets {
return UIEdgeInsets(top: 10, left: 10, bottom: 10, right: 10)
}
override var intrinsicContentSize: CGSize {
var size = super.intrinsicContentSize
size.width += alignmentRectInsets.left + alignmentRectInsets.right
size.height += alignmentRectInsets.top + alignmentRectInsets.bottom
return size
}
private var boundsInsetByAlignmentRect: CGRect {
return UIEdgeInsetsInsetRect(bounds, alignmentRectInsets)
}
override func backgroundRect(forBounds bounds: CGRect) -> CGRect {
return super.backgroundRect(forBounds: boundsInsetByAlignmentRect)
}
override func imageRect(forContentRect contentRect: CGRect) -> CGRect {
return super.imageRect(forContentRect: boundsInsetByAlignmentRect)
}
override func titleRect(forContentRect contentRect: CGRect) -> CGRect {
return super.titleRect(forContentRect: boundsInsetByAlignmentRect)
}
}
This gives us a button where the frame is slightly bigger, but things are positioned relative to the original size:

It is worth pointing out that this will not work inside a UIStackView since the larger frame will extend outside the bounds of its container and UIStackView is fairly aggressive about ignoring outside touches.
If outside views are opaque and do not cause blending or offscreen rendering, it does not appear there are any additional costs to having subviews drawing outside bounds.
Better shadow performance on views
There are two different uses for the shadowPath property on CALayer:
For performance reasons, always set a shadowPath. This is a substantial improvement, especially if the view changes position via animation or presence in a scroll view.
When you can set a path
The shadowPath tells the system what should be casting a shadow without having to look at the contents of the view itself. Since most views that need a shadow are opaque, we just need to describe the appearance of the background of the view.
Using the convenience initializers on UIBezierPath we can create ovals, squares and rounded rectangles without difficulty. For more complicated paths, check out A Primer on Bézier Curves. You can still use UIBezierPath or CGPath to create them, but it will require more complicated math.
Starting with a simple, purple view with a shadow:
let purpleView = UIView()
purpleView.backgroundColor = .purple
purpleView.layer.shadowRadius = 10.0
purpleView.layer.shadowColor = UIColor.black.cgColor
purpleView.layer.shadowOffset = CGSize()
purpleView.layer.shadowOpacity = 0.8
We can tell the system to draw a shadow for the entire square:
purpleView.layer.shadowPath = UIBezierPath(rect: purpleView.bounds).cgPath

For rounded corners, we can set the cornerRadius property on the layer, and create a matching shadowPath:
purpleView.layer.cornerRadius = 16.0
purpleView.layer.shadowPath = UIBezierPath(roundedRect: view.bounds, cornerRadius: 16.0).cgPath

When you can’t set a path
Sometimes it’s not possible to set a path because there’s no easy way to describe the contents of the view. For example, text is a mess of random contents. Rasterizing the layer avoids having to draw the shadow repeatedly.
// create our label
let label = UILabel()
label.textColor = .purple
label.text = NSLocalizedString("Swift Lemma!", comment: "")
label.layer.shadowOpacity = 0.6
label.layer.shadowColor = UIColor.black.cgColor
label.layer.shadowOffset = CGSize(width: 0, height: 2)
// render and cache the layer
label.layer.shouldRasterize = true
// make sure the cache is retina (the default is 1.0)
label.layer.rasterizationScale = UIScreen.main.scale
This produces a view that looks like this:

Keep in mind
Always set the shadowPath inside either layoutSubviews() or viewDidLayoutSubviews(). Since Auto Layout likely means there aren’t constant sizes for views, setting a shadowPath elsewhere may become outdated or incorrect.
When creating a path, the coordinate system for the path is the layer it’s applied to. To make it easier, pretend the shadow path is a subview. For this reason, we use the bounds of the view to create its shadow path.
Layout margins within a UIStackView
The UIStackView property isLayoutMarginsRelativeArrangement allows insets similar to margin constraints on subviews in a UIView.
Let’s consider a simple single-subview example:
let containedView = UIView()
containedView.backgroundColor = .purple
let stackView = UIStackView()
stackView.addArrangedSubview(containedView)
You can then configure directionalLayoutMargins and enable them like so:
stackView.directionalLayoutMargins = NSDirectionalEdgeInsets(
top: 8,
leading: 8,
bottom: 8,
trailing: 8
)
stackView.isLayoutMarginsRelativeArrangement = true
This is what it looks like, before and after:


Is using a generic top-level domain a good idea?
I’ve been thinking about switching over my website and email to one of the new top-level domains. This has lead me to investigating what the switch would feel like, and how stable the move would be.
Will it survive?
I am looking at the .engineer gTLD now owned by Donuts. At the time of writing this, there are a total of 2706 registered domains since late 2014. That’s nothing.
That got me thinking: what exactly happens when a gTLD fails?
The answers aren’t clear. When applying, ICANN requires registrars put up cash in the form of a bond to cover operational costs for 3 years. If a registrar were to fail, another can propose to take over. Their database is stored off-site, and data can be migrated.
But what if nobody does? What happens to a gTLD if there’s not enough domains to stay in business? The answer, it seems, is that the domain ends. There’s no provisions at ICANN to maintain domains beyond the transfer procedure.
Donuts, for what it’s worth, has stated they would not shut any down:
We think of all the TLDs as one big registry. It[’]s profitable, so all our TLDs are profitable, but that is beside the point. We’d no more shut down one of our TLDs than you would shut down 100 “unprofitable” second-level names in .link.
There’s definitely risk, and that’s not what the internet needs. It should be that, regardless of the fate of any registrar, a domain you purchase today will be valid as long as you renew it.
As an email
Generic top-level domains have been available for registration since 2013, but there’s a number of services that can’t handle them. I’m surprised how many times I enter one into an email field and see “invalid address” as the result.
The responses I’ve received are generally the “doing it wrong” variety and not the “I’ve filed an issue and we’ll look into it.” I’m not sure what I expected to be honest; I hoped that it would be passed up the food chain, but it always dies in the first round of support.
This means, to use a gTLD, I need to keep a backup domain for services like AT&T, CBS, Virgin Airlines, and Crunchyroll. I expected that in 2017 it wouldn’t be a problem, and for the most part it isn’t an issue. It’s frustrating though.
Premium domains
New.net tried replacing ICANN’s authority in the past, long before gTLDs existed. They offered some snazzy options, and I grabbed zac.tech to play around. It didn’t work on most ISPs, but it did work on mine.
That’s a valid gTLD now! I could register it again! For the low, low cost of $2800. Per year.
This notion of a premium domain name is a money-grab by registrars. What constitutes a “premium” domain is arbitrary: length, dictionary words, prettiness, etc. If you try to register one of these domains at NearlyFreeSpeech you get a perfectly correct error:
This means the registry of this gTLD plans to extort extra money from anyone who wants this domain.
It is, and they do. These premium prices may come down. Perhaps they’ll stop charging extra to renew them entirely. But when your registry has a few thousand total domains are premium bottlenecks the right way to go about this?
The future?
I’m worried that entire namespaces are being taken by companies for their internal use, like Google seems to be doing with .dev. If you’ve got the cash, you can take complete, even dictatorial, ownership. That’s not how existing domains worked, but it’s the rules we’re living under with ICANN’s leadership.
But we can’t continue to have one namespace. We’ve been in a world where everything but .com was wrong, and Verisign’s control over it has been harsh. These new top-level domains are nicer looking and there’s significantly more availability.
So I’m thinking about switching. There’s a lot to choose from, and more opening up every day. I’m on a ccTLD right now, and there’s a real risk that it could go away at any time through local laws or disputes. Remember when every startup was using Libya’s .ly domain?
Generic top-level domains feel like an improvement for the internet as a whole. The cruft at the end doesn’t have to be cruft; it can be descriptive, it can be helpful, and above all it can be nice.
Automating iOS app builds
I believe an important part of the development process is getting a working version into the hands of others. As part of this, being able to install the latest and greatest on the fly is paramount. It took me a lot of time to find a reliable way to build, sign, and distribute apps as part of this internal continuous delivery.
I do not recommend running your own build machines. Wasted days with Jenkins failing and Xcode crashing have taught me this is the most fragile part—and worth outsourcing. Fortunately, there are now companies dedicated to it. CircleCI has served me well: their support is fantastic and their service, despite the beta label, is very reliable. You might need to send them a quick message to request access.
Below is the outline of creating a script to generate builds. My goal isn’t to create a file you can copy-and-paste, rather to describe the methodology. If you want a full solution, I hear good things about fastlane.
Configure deployment
To instruct CircleCI to run a distribution script, add a deployment step like the following to your circle.yml file. You can find more information in the CircleCI iOS docs.
machine:
xcode:
version: 6.3.1 # We want nullability, etc.
deployment:
s3:
branch: /.*/ # All branches
commands:
- ./your-directory/your-script.sh | tee $CIRCLE_ARTIFACTS/distribute.log:
timeout: 600
I like to log the build verbosely, so I save the entire transcript as an artifact. This makes it a lot easier to find compile issues. Note the timeout key is indented another level below the script command, which is a key itself. YAML syntax is strange.
Create a keychain
The most complicated part is handling your signing credentials. I’ve found that the simplest and most secure solution is a keychain checked into the repository. To store your private key and Apple-signed certificate, let’s create one:
Using a keychain directly allows Xcode’s tools access to your credentials. It’s also easy to update: just repeat the above steps with your existing keychain after renewing your certificate. You can include as many signing identities as you wish in the same keychain: enterprise, ad-hoc, App Store, etc.
Use the keychain to codesign builds
Create an environmental variable (here named IOS_CI_KEYCHAIN_PASSWORD) with the password you created above. Don’t store this within your repository.
Command-line operations require absolute paths to the keychain file, so we need to save that into a variable. This example assumes you’re executing a script in the same directory as the keychain:
# Make any command erroring fail the whole script
set -e
# Get the absolute keychain path - `security` requires absolute paths
pushd $(dirname $0)
TOOLS_PATH=$(pwd)
popd
KEYCHAIN_NAME="$TOOLS_PATH/distribute.keychain"
With our keychain’s absolute location, we can now:
Note: If you run the following locally, you will lose access to your keychain. To fix it, instead use the absolute path to $HOME/Library/Keychains/login.keychain.
# Set our keychain as the search path. Don't run this locally.
security list-keychains -s "$KEYCHAIN_NAME"
# Unlock it using the environmental variable.
security unlock-keychain -p "$IOS_CI_KEYCHAIN_PASSWORD" "$KEYCHAIN_NAME"
# Make sure we have a long timeout window.
security set-keychain-settings -t 3600 -u "$KEYCHAIN_NAME"
function cleanup {
# Clean up on any kind of exit, just in case something bad happens.
echo "Cleaning up keychain due to exit"
security lock-keychain -a
}
trap cleanup EXIT
When run, your commands will have access to your certificates and keys until the script exits cleanly or otherwise.
Copy provisioning profiles
You will also need the provisioning profiles you’ve configured in Xcode. For simplicity’s sake, don’t bother figuring out which; just copy everything into your repository.
PROVISIONING_SYSTEM="$HOME/Library/MobileDevice/Provisioning Profiles/"
PROVISIONING_LOCAL="$TOOLS_PATH/provisioning-profiles/"
mkdir -p "$PROVISIONING_SYSTEM"
find "$PROVISIONING_LOCAL" -type f -exec cp '{}' "$PROVISIONING_SYSTEM" \;
You can add an rm -rf "$PROVISIONING_SYSTEM" to the cleanup function as well.
Create and upload the build
Building .ipa files is unnecessarily hard. I don’t know why. I use Nomad, which cleanly wraps the somewhat-private Xcode commands.
Nomad supports many upload destinations and services; for file storage, I like to use S3. Its library uses AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY environmental variables, which you should create as a new limited-access IAM user.
# Where to store the IPA. CircleCI has an artifacts folder you can stuff things into.
# Some other providers seem to lack this, so perhaps use /tmp/.
IPA_NAME="$CIRCLE_ARTIFACTS/$CIRCLE_BRANCH.ipa"
# Disable archive because otherwise it will build twice, wasting time.
# If you aren't using Bundler (you should, though), drop the `bundle exec` part.
bundle exec ipa build --no-archive --verbose --ipa "$IPA_NAME"
bundle exec ipa distribute:s3 -b "your-bucket-name" -f "$IPA_NAME"
You may also use Nomad to upload additional files like the dSYM to your crash reporting service, metadata like the latest build number from agvtool, or certain branches directly to iTunes Connect.
Install on device
Name files by branch. This makes testing somebody’s idea or feature extremely easy. The iOS Deployment Reference gives you all you need to get started. Basically, you need an itms:// link pointing to a .plist file pointing to the .ipa file. It’s quite easy.
Localizing attributed strings on iOS
In an iOS app, localization can be especially difficult when dealing with attributed strings. Fairly often, designers request something like:
Read our Terms of Service, Privacy Policy, or contact us with any questions.
or like:
Searching for burgers in SOMA, San Francisco, CA:
The golden rule of localized strings is to treat them as atomic units:
Often these complexities are cited as reasons to avoid localization. But, unless you have geographic constraints, you will find a substantially larger audience with a localized application.
ZSWTappableLabel and ZSWTaggedString are two open-source libraries I have released to help solve these problems.
ZSWTappableLabel makes links inside your attributed strings tappable, as the name suggests. It’s a UILabel subclass which does not do any drawing itself, making it fast and easy.
ZSWTaggedString is the powerhouse. It transforms an HTML-like syntax into an attributed string. You can read more about the syntax and advanced usage on its GitHub page, but here’s how you might use it for the examples above:
Read our <i><tos>Terms of Service</tos></i>, <i><privacy>Privacy Policy</privacy></i>, or <i><contact>contact us</contact></i> with any questions.
Searching for <term>%@</term> in <location>%@</location>:
In my experience, localizers1 are familiar enough with HTML to have no issues with localizing these strings. By marking the regions you intend to be visually distinct, they can more easily understand your intent, producing better localizations.
While on the subject, here are a few best practices for localization in iOS:
Read more tips and tricks at NSHipster about NSLocalizedString and NSLocale.
T-Mobile: good ideas, bad experience
When T-Mobile entered the wireless scene as the “Uncarrier” I was impressed. Their greatest contribution to the carrier ecosystem is consistently adding features, forcing other carriers to keep up. Instead of rationed text and voice, we’re in a world where data is king.
However, if you are considering T-Mobile service, I suggest reconsidering. The plans and features look appetizing, but their execution leaves a lot to be desired. I would not count on their unique features; just the now-basics with worse coverage.
I wrote off my initial experiences as anecdotal, but it became cumulatively enough for me to leave their service.
Free data for life on tablets
My first experience with the new T-Mobile was their offer of free monthly 200mb of data. It’s a compelling reason to go with them.
After a month of lifetime free data, it ended and I got “could not connect to data service” errors. The first rep I spoke with ran me through the usual steps culminating in toggling something on his side and waiting 48 hours to see if it worked.
The next rep a couple days later insisted I had to reformat without restoring a backup. This was a huge pain, and unsurprisingly didn’t fix anything. He filed a report with “the engineers.”
A few more days later, service started working again, and later the rep called to make sure. The follow-up made me happy, despite the length of time from start to finish.
Update 2014-12-29: After moving my cell phone from T-Mobile to AT&T, I started receiving a bill for $10/mo for my “free data for life” device. I called and received a credit the first time, but dug into it more the second time.
Their retention department informed me that the “free data for life” offer requires having another device with T-Mobile service. According to their press release (backup) no such qualifier existed when I signed up, and according to their second press release (backup) “there is no $10.00 per month fee for the 200MB of free data.”
I see no qualifiers on their support page so I can only assume their screw-the-customer attitude is behind-the-scenes policy.
Refer-a-friend bonus
There’s no zealot like a convert, and I convinced a few friends to switch their service over. When T-Mobile announced a new referral system, wherein both sides get unlimited data for a year, my latest referral and I signed up.
I received only a $25 in-store gift card, and waited a few weeks to call the refer-a-friend support to figure out why. I was immediately told it was a mistake, and the rep said he would add unlimited data to my plan.
I asked for clarification on the change, and he confirmed it was “free for 12 months,” and suggested my friend call, too. Another rep added unlimited data to my friend’s account.
Not-so-bonus
My bill went up by $50, or $20 more than just adding unlimited data would cost. My friend’s bill went up, too.
When I called support, the first rep clarified that my referral would only give me a $10 discount on unlimited service. After expressing confusion, she placed me on hold to ask refer-a-friend support.
The phone rang, and I was greeted with, “T-Mobile refer-a-friend support, how can I help you?” I was blindly transferred, and had to explain everything for the second time.
This rep said a few things, and I got the impression he believed I added unlimited data myself:
The net result is I would have to pay $20 extra monthly to get unlimited data, which should have been free twice over. I asked him to take off the unlimited data charge, and he placed me on hold.
And then I heard, “all of our representatives are busy, please hold,” and got to explain everything again to a third rep I was blindly transferred to. This final rep was nice enough to credit the plan and remove unlimited data from my account, at least, even though she accidentally hung up on me towards the end.
I complained about this on Twitter and although their Twitter presence contacted me, they never responded days after asking for my phone number.1
Free texting in the air
I had the opportunity to give another new benefit a try: on Gogo in-flight internet, devices already set up for WiFi calling can connect to the network for SMS service. This did not work.
When it came time to “get started” on the T-Mobile side of things, I received errors repeatedly and I gave up. Gogo support was nice enough to credit a free hour of internet for my troubles, which is a fine example of what I’m really looking for: solutions.
Goodbye
T-Mobile is a noble experiment executed with good intentions but badly in need of restructuring. Every time I try a perk, it backfires, and I don’t care to spend hours fighting.
I am switching to AT&T to pay the same amount. If there’s one good thing T-Mobile is doing, it’s pushing the other carriers to offer competitive plans. However, issues with implementation make their poor coverage feel even worse. Hopefully this changes in the years to come.
Enabling bridge mode on AT&T U-verse
These are instructions to configure a U-verse gateway to send all of its incoming traffic to your own router without impacting its normal networking services.
The gateway
The gateway model that I am using is a 2Wire/Pace 3800HGV-B, but these instructions likely work for similar models.
You can connect to it at 192.168.1.254. This service is abysmally slow and fairly hard to navigate as a result. The gateway will on occasion prompt for the password labeled “system password” on its serial number sticker.
Turning on DMZplus
First, we need to forward all of the traffic to the router. This can be done as follows:
Assigning a public IP
Finally, we need to give the router the knowledge that it’s a public-facing device. UPnP and NAT-PMP rely on determining the public IP, and having the correct WAN IP is required for many routers.
We can achieve this by assigning the router the public IP address as follows:
All done
After the router renews its DHCP lease, it will be assigned the public IP address. This is generally a huge button labeled “Renew DHCP Lease” or a power cable plugged into the device.
U-verse IP addresses are dynamic, but are deterministic from hardware configurations on their end. Thankfully, this means the addresses very rarely change. I’ve gotten away with just adding an A record to a random domain name to make it easy to access my VPN.
Saving optimal JPEGs on iOS
Conventional wisdom for creating a JPEG version of a UIImage is first to turn it into an NSData and immediately write it to disk like so:
NSData *jpegRepresentation = UIImageJPEGRepresentation(image, 0.94);
[jpegRepresentation writeToFile:outputURL.path
atomically:NO];
Most of the time this is exactly right. However, if file size is important, Image IO is a great alternative. It is a powerful system framework to read and write images, and produces smaller files at the same compression level.
Why Image IO?
A project I am working on requires uploading photos en masse. Low upload bandwidth makes file size a limiting factor, so I sought out ways to reduce it.
I put together a test project to find the differences between the two methods. The results are pretty interesting:
The only discernible visual difference is the grain in the images, but even that is minor. Here’s a diff between two versions of the same original photo:

Using Image IO
First, you’ll need to add two new framework dependencies:
@import ImageIO; // to do the actual work
@import MobileCoreServices; // for the type defines
When creating your JPEG file, the first step is to create a CGImageDestinationRef specifying where to write the result:
CGImageDestinationRef destinationRef =
CGImageDestinationCreateWithURL((__bridge CFURLRef)outputURL,
/* file type */ kUTTypeJPEG,
/* number of images */ 1,
/* reserved */ NULL);
Image IO is able to produce files of a few different types2 but my focus here is JPEGs. Next, we set up the properties of the output file, specifying a constant compression factor:
NSDictionary *properties = @{
(__bridge NSString *)kCGImageDestinationLossyCompressionQuality: @(0.94)
};
CGImageDestinationSetProperties(destinationRef,
(__bridge CFDictionaryRef)properties);
And, importantly, we specify what is to be written out:
CGImageDestinationAddImage(destinationRef,
/* image */ image.CGImage,
/* properties */ NULL);
And finally, we write it to disk and clean up the reference:
CGImageDestinationFinalize(destinationRef);
CFRelease(destinationRef);
Using the Xcode Structure menu
Xcode’s Editor > Structure menu has a few great actions:
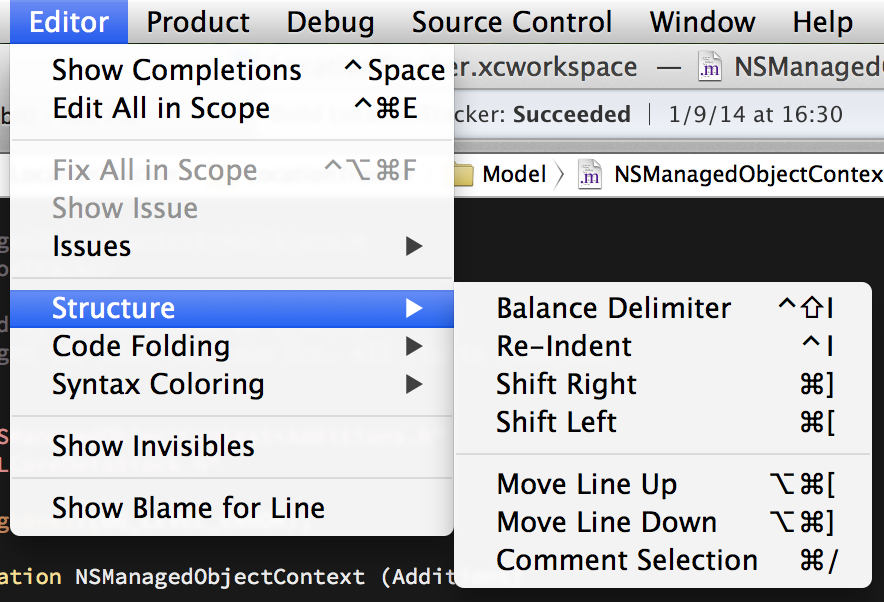
These actions all act on either your cursor position or selection.
Balance Delimiter
Normally you can double-click quotes, brackets, or parenthesis to select the matching character and all text in-between. The Balance Delimiter behaves similarly: it looks at your cursor position (or selection), finds the nearest pair and selects in-between.
This doesn’t have a default keyboard shortcut, but you can set one up in Xcode’s Key Bindings preferences. I set it to ⇧⌃I since I use it in similar ways to Re-Indent.
Re-Indent ⌃I
Objective-C is a fairly indentation-heavy language, and Xcode generally does a good job at indenting while you’re typing. However, if you’re pasting text or refactoring things can get pretty hairy, so let Xcode fix up your code for you with Re-Indent.
Shift Left ⌘[, Shift Right ⌘]
You can also indent manually using the Shift Left and Shift Right actions, which unindent or indent by one tab, respectively. They do exactly what they say on the tin.
Move Line Up ⌥⌘[, Move Line Down ⌥⌘]
These actions move your current line (or selection) up or down by one line. Simple, right? What’s really useful is that it is context-aware: they understand going in and out of control flow or blocks. Much faster than cutting, pasting and re-indenting each time.
Comment Selection ⌘/
Rather than wrapping your code in /* … */ and dealing with the conflicting multi-line comments you probably already have, simply select what you want to temporarily eliminate and hit the shortcut. Each line selected is then prefixed by //.
Error arguments in Objective-C
From the Programming with Objective-C (backup) overview from Apple:
When dealing with errors passed by reference, it’s important to test the return value of the method to see whether an error occurred, as shown above. Don’t just test to see whether the error pointer was set to point to an error.
and from the Error Handling Programming Guide (backup):
Success or failure is indicated by the return value of the method. Although Cocoa methods that indirectly return error objects in the Cocoa error domain are guaranteed to return such objects if the method indicates failure by directly returning
nilorNO, you should always check that the return value isnilorNObefore attempting to do anything with theNSErrorobject.
For example, let’s say we’re executing a fetch request:
NSError *error = nil;
NSFetchRequest *request = /* … */;
NSArray *objects = [context executeFetchRequest:request
error:&error];
To test if the fetch was successful, we must do:
if (objects) {
// hooray!
} else {
NSLog(@"Got an error: %@", error);
}
A method taking an NSError ** does not guarantee how it is used when successful. In this case, even a successful method call may end up with error set to something other than nil.